PART-1 : Text-Classification techniques on subtitles of YouTube.

This blog focuses on various types of text-classifications techniques on YouTube subtitles in Machine Learning
Contents
- Making Data and Analysis- Defining problem statement- Text Classification Techniques - Using BOW
- Using TF-IDF
Making Data and Analysis
Google Colab link
Follow the above Google Colab Link made by me to understand how I made the data and did some analysis for this blog ,
Summary of Google Colab
1) The data has two columns- subtitles , labels
2) Labels have the values : 0- “Entertainment” , 1- “Academic”.
Observations
1) Both the labels are quite Imbalanced in the main data frame
2) The language present in the dataframe are of various kinds — English , French , etc and kept only english language.
3) The length of the subtitles exceeds the range of 100000 in some cases.
4) The number of entities present in a subtitle file can be more than 1000 in some cases.

Defining Problem Statement
“Classify Text into Academic and Entertainment”.
“In ML problem statement , a binary classification of text into Academic and Entertainment”.
Dictionary for Text preprocessing :1) Stop Word Removal : Removing stop words
2) Lower-Case : Converting to lower case
3) Stemming : Use the base for all the congruent words.
4) Lemmatization : Breaking of a sentence into words.
Text Classification Techniques
For text classification ,or rather any techniques related to text , it is important to understand why a text is always converted to a vector .
t1 and t2 are two texts , v1 and v2 are representations of them ,if similarity t1 and t2 is greater :
distance(v1 , v2) is very small
Due to the above property , similar text can be clustered together which gives a way to classify text to various sub-categories. The below text classification techniques are following the same property and have their unique property to convert a text to a d-dimensional vector , which then is used to classify text to the various categories.
Note : At every end of a technique , a google Colab link is given , to give an understanding of the concept and how to use it in code ,some main points in google Colab are
- It uses “Random-Forrest-Classifier” as a baseline model.
- The main metric used is “F1-Score”.
- “T-SNE” for visualization /Effectiveness of the approach.
Using Bag of Words (BOW)
This is one of the most simple and also an effective approach to convert a text into a d-dimensional vector , lets understand BOW with an example -
#Notations
corpus: [ “math is logical”,
“my name is Raghav”,
“Data is information”]corpus[i]: Document#Steps1. Getting all the unique words in the corpus with removal of stop words (removal of stop words is not necessary always):-> math | logical | name | raghav | data | information-> convert to vector : [ , , , , , ]2. Considering this a vector making a vector for each document in the whole corpus:[[1,1,0,0,0,0],[0,0,1,1,0,0],[0,0,0,0,1,1]]
Such simple and effective approach often works well in many problem statements , and give a great results for classification problems , intuitively if we take the above example and our problem statement , words like “math” , “logical” , “data” , “information” will have contribution for the model to understand that weather the sentence is academic or not.
Using this same method , we make our vocab using our train data corpus and using the vocab , we convert our data to a BOW-featurized data.

Results for the problem statement
T-SNE

Random-Forrest-Classifier

Summary1. Using BOW was an effective approach for this problem.2. 9749 features were made using BOW features , with n_gram = 13. T-SNE gave very good results , as the data was seen to be very differentiable in terms of visualization.4. For Random-Forrest , F1 — Score for Test dataset : 0.90
Using TF-IDF
Term Frequency -Inverse Document Frequency is a way to convert a text into a vector such that-
1. More importance to more frequent words in a particular document
2. More importance to rarer words in the whole corpusFollowing the two rules mentioned above -
Term Frequency
To give more importance to frequent words in a particular document , Term frequency is used, the formula is as follows
#Notations
Corpus = [ "w1 , w2 , w3 , w1 , w5" ,
"w3 , w2 , w5 , w1 , w7" ,
"w4 , w9 , w2 , w1 , w4" ]
Document[i] = Corpus[i]#Formula
number of times w_i in D_i
Term_Frequency(w_i , D_i) = ---------------------------
Total number of words in D_i
Inverse Document Frequency
To give more importance to rarer words in the document ,Inverse Document frequency is used , the formula is as follows
number of Documents
Inverse_Doc_Freq(w_i , Corpus) = log( ---------------------- )
number of Doc with w_i Hence,
TF-IDF(w_i , D_i , Corpus) = TF(w_i , D_i) * IDF(w_i , Corpus) Why log in IDF ?
The value of IDF without “log” , can become very large and due to which the complexity is high,
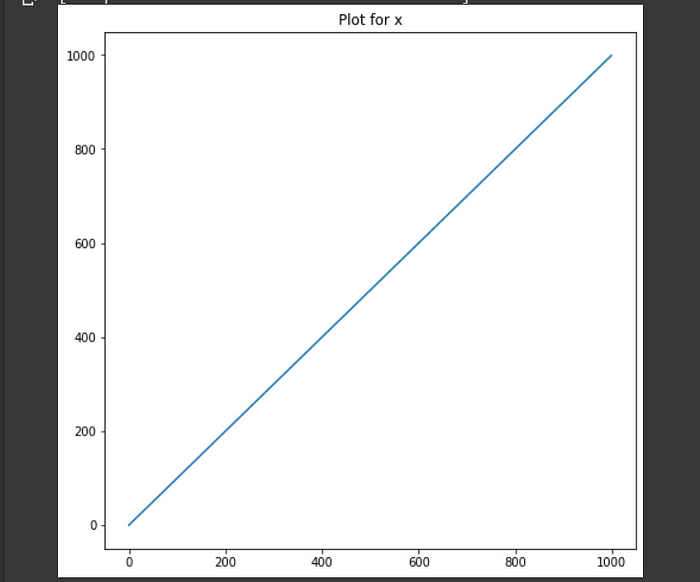


let,
#N = number of Documents
#ni = number of Doc with w_iFor the above graph , the “Red” line is #N/#ni and “Silver” line is log(#N/#ni) , both are increasing but at very different rates.
In the function , log is monotonous , so #N / #ni and log(#N / #ni) has same behavior but log complexity is fast , and if log is not used for idf , for the whole tf-idf equation , idf will dominate the equation. Hence, log is used.
Results for the problem statement
T-SNE

Random Forrest Classifier

Summary 1. Using TF-IDF was an effective approach for this problem.2. 135762 features were made using BOW features , with n_gram = 13. T-SNE gave very good results , as the data was seen more differentiable than BOW in terms of visualization.4. For Random-Forrest , F1 - Score for Test dataset : 0.903
Summary
Bag of words and TF-IDF are the most standard/classical approaches anyone can follow and do the classification for the particular dataset , following a particular problem statement.
Hope this blogs give a good foundation on topics related to text-classification
Thank you.
My LinkedIn
Further Reading
As shown in the starting of the blog , this is a part-1 to text classification in ML , in the Part-2,with certain shift , it will give the understanding of training a Neural Network, understanding these two together gives a good base to all the text related solutions and problems out there.
